Содержание
- 1 Обзор PRO-версии программы Netpeak Spider: Мультидоменное сканирование, Выгрузка из GSC, White label
- 2 Парсинг товаров с сайта интернет магазина в таблицу
- 3 Настройки парсинга данных «Netpeak Spider»
- 4 Экспорт результатов парсинга
- 5 Заключение
- 6 Быстрый доступ к проектам
- 7 Визуализация данных
- 8 Расчет PageRank
- 9 Проверка индексации страниц
- 10 Дашборд
- 11 Заключение
Программа Netpeak Spider 3.6 – профессиональный инструмент для SEO-специалистов.
Лень читать статью? Посмотри видео:
Обзор PRO-версии программы Netpeak Spider: Мультидоменное сканирование, Выгрузка из GSC, White label
Время прочтения: Программа Netpeak Spider – это мощный инструмент на вооружении у SEO-специалиста.
Можно скачать бесплатную тестовую версию с официального сайта: Netpeak Launcher (Для Windows 7 и выше).
В течении 7 дней теста, можно провести полноценный аудит сайта без ограничений, найти многие недочеты и устранить их.
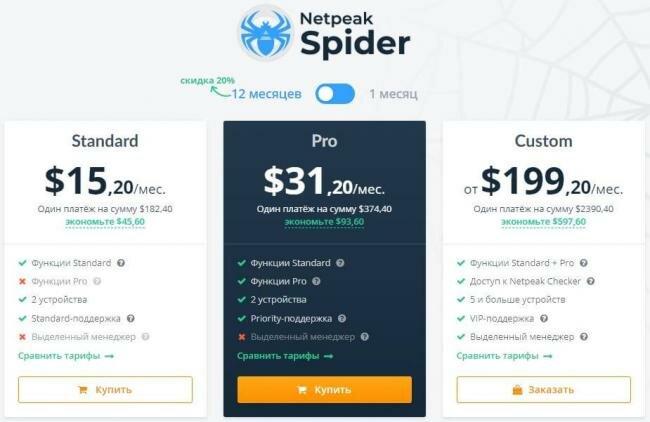
Для профессиональной работы вы можете купить программу с 10% скидкой по промокоду: 9ea5aab9 или по ссылке: скачать
Промокоды
Компания Netpeak Software устроили распродажу софта со скидками до 45% на все тарифные планы. Ловите купоны:
- -25% на Netpeak Spider или Checker на 1 месяц по промокоду Soltyk-Z25 (Экономия до $9,75)
- -35% на Netpeak Spider или Checker на 12 месяцев по промокоду Soltyk-Z35 (Экономия до $131)
- -45% на покупку сразу двух продуктов Netpeak Spider + Checker на 12 месяцев по промокоду Soltyk-Z45 (Экономия до $250)
Акция действует до 24 апреля включительно! Запасайтесь лицензиями (их можно активировать в любое время).
Возможности
Рассмотрим основные возможности этого инструмента:
- Проверка более 70 важных технических параметров сайта на каждой странице;
- Получение структуры сайта;
- Анализ внутренней перелинковки;
- Генерация и валидация Sitemap;
- Подготовка сайта к редизайну и переезду, смене CMS;
- Быстрая работа с огромными сайтами (я сканировал сайты объемами более 6 миллионов страниц);
- Анализ сайтов конкурентов (SEO, контент-стратегии и другое);
- Парсинг различных данных, к примеру мониторинг цен товаров на сайтах конкурентов;
- Поиск точек роста ресурса;
- Возможность анализа по разным сегментам;
- Отчеты об эффективности продвижения;
- Контроль внедрения исправлений и улучшений.
Закажите онлайн-демонстрацию возможностей и узнайте, как пользоваться программой.
 MegaIndex: технологический лидер в области автоматизированного продвижения сайтов
MegaIndex: технологический лидер в области автоматизированного продвижения сайтовМультидоменное сканирование
Если есть необходимость сканировать сразу несколько доменов вглубь за сессию.
К примеру, можно парсить страницы по списку сайтов. Такая возможность есть на тарифе PRO.
Включение функции производится в основных настройках:

Все URL которые будут добавлены в таблицу или в поле “Начальный URL” – будут просканированы.
Выгрузка из GSC
С помощью интересной функции в Netpeak Spider можно производить более быстрый и качественный анализ ключевых фраз из Google Search Console по всем страницам.
Есть методология повышения релевантности контента.
Самое простое это оптимизация заголовков Title и H1 – как базовые элементы релевантности страницы.
Можно конечно вручную смотреть поисковые запросы для каждой страницы с ограничением в 1000 запросов на выгрузку… отдельно выгружать…
 Используем Serpstat на реальных примерах анализа конкурентов + 10 практических кейсов
Используем Serpstat на реальных примерах анализа конкурентов + 10 практических кейсовКак это делается вручную в GSC на примере моего интернет-магазина:
</ul></ul>
- Переходим в раздел «Эффективность» (1), затем изменяем период с 3 до 16 месяцев (2):
- Это необходимо чтобы получить большую выборку по страницам.
- Включаем отображение показателей «Средний CTR» и «Средняя позиция»:
- Переходим на вкладку «Страницы» (1) и выбираем, к примеру, самый кликабельный URL (2):
- Переходим во вкладку «Запросы» (2) и видим результаты с фильтрацией по выбранному URL (1):
Сортировка по параметрам:
</ol>
- Клики (3) – это то что больше 0 и является для нас критически важным. Сконцентрируйте внимание на этих запросах.
- Показы (4) – чем больше показов, тем выше релевантность документа этому запросу, это своеобразная точная частотность запросов.
- CTR (5) – чем выше значение, тем сильнее соответствие сниппета интенту запроса.
- Позиции (6) – если отсортировать на увеличение, то первые фразы будут с большей вероятностью самыми релевантными (по «мнению» поисковой системы).
Определившись с наиболее релевантными запросами попробуйте составить Title, который будет релевантным и отображать основную суть документа.
Данные из ЯВ
Кроме того, есть еще подход в подобном анализе страниц с помощью Яндекс.Вебмастера.
Я писал в техническую поддержу Netpeak Software с идеей чтобы получать запросы из Яндекса по аналогии, но пока это невозможно из-за ограничений по API.
И так лайвхак:
</ul>
 Fo.ru – конструктор для создания сайтов – инструкция, описание, возможности
Fo.ru – конструктор для создания сайтов – инструкция, описание, возможности- Переходим в Яндекс.Вебмастер.
- В разделе «Поисковые запросы» (1) переходим в «Рекомендованные запросы» (2).
Смотрим только те запросы, по которым есть показы (3), т.е. есть релевантность документа и мы можем повысить соответствие заголовков этим запросам.
Нажимаем фильтрацию, чтобы выбрать данные только по нужному нам URL (4):
Выбрав пункт «URL, условия» (1), вставляем исследуемый URL (2).
Чтобы включить режим регулярного выражения, добавляем знак ~ в начале URL (3).
А чтобы обозначить конец URL – добавляем знак доллара $ в конец ссылки (4). Нажимаем «Применить» (5):
Тут аналогично как Google Search Console:
- Прогноз показов (за 30 дней) – общая частотность, лучше не заострять внимание на этой сортировке, т.к. точная частотность может быть крайне низкой.
- Прогноз кликов (за 30 дней) – примерный, но более приближенный показатель к точной частоте. Рекомендую сортировать по нему.
- Прогноз цены клика (в рублях) – чем больше стоимость, тем выше конкуренция. Показатель больше для контекстологов.
- Текущая позиция страницы в поиске – Средневзвешенная по показам позиция в поиске за последние 30 дней. Сортируйте по ней, чтобы понять какие запросы наиболее релевантные.
Ручная корректировка каждой страницы при совмещении техник сразу по данным обоих поисковых систем может занимать длительное время.
Netpeak Spider 3.6: запросы из Search Console
Можно автоматизировать получение запросов по каждой страницы с помощью обновленной программы Netpeak Spider. Теперь не нужно ручного «колхоза»!
Эта функция доступна только на тарифе PRO.
Чтобы её включить, необходимо перейти в «Настройки» (1) и перейти в раздел «Google Analytics и Search Console» (2):
Для начала работы необходимо добавить аккаунт Google:
В открывшемся окне вам необходимо будет активировать аккаунт, к которому будет предоставлен доступ приложению Netpeak Spider.
Щелкните по активному аккаунту (1), или добавьте нужный (2):
Разрешите доступ к Google Analytics:
Разрешите доступ к Google Search Console:
После этого еще раз подтвердите свои намерения:
Выберите диапазон дат:
«Последние 365 дней», т.е. данные за год – наиболее оптимальный период для получения статистики по запросам.
Можно конечно еще выбрать кастомный период равный 16 месяцам (аналог в GSC):
Больше данного периода вы не получите результаты. Рекомендую, не заморачиваться с периодами и просто брать последние 365 дней, чтобы получить больше данных по фразам.
Включаем выгрузку запросов из Search Console:
Если запросы блокируются – установите галочку по использованию прокси.
Нажимаем «ОК» и начинанием парсинг сайта.
Сканируем сайт интернет-магазина с помощью Netpeak Spider
Настройки сканирования можно использовать по умолчанию.
Вставляем URL домена (1) и запускаем нажимаем кнопку «Старт» (2):
После стандартного сканирования нажимаем “Загрузить из Google Analytics” в меню:
Аналогично получаем другие URL из Google Search Console:
После этого добавляются страницы, которые при обычном обходе по внутренним ссылкам сайта были не известны:
Продолжаем сканирование… Нажимаем кнопку “Старт”.
По завершению сканирования можно выгрузить все запросы для всех страниц – в меню “База данных” находим пункт “GSC: Запросы”:
В выгруженных запроса можно выделить сразу наиболее приоритетные фразы.
В период за год (365 дней), применяем следующие фильтры:
</ol></ol>
- Клики более 0 – запросы которые приносят нам переходы, важны и являются приоритетными;
- Показы от 100 – мы отсекаем фразы с единичными показами. Это своего рода точная частотность показа URL в поиске по данному запросу.
Применяем фильтр “И” – т.е. выполняется жесткий отбор качественных запросов. На основе их формируем заголовок Title.
Применяем фильтр “ИЛИ” – т.е. совмещаем те и другие поисковые фразы. Это позволит оптимизировать другие текстовые зоны на странице, к примеру, description + заголовки h2-h4.
Как получить запросы по сайту с нужной нам Страны?
Переходим в настройки для Google и расширяем данные по странам при выгрузке запросов:
Подтверждаем, после чего переходим в раздет меню “Анализ” и нажимаем “Выгрузить запросы из Search Console”:
После чего произойдет обновление данных:
Повторяем действие, переходим к результатам:
Мы можем отфильтровать аналогично по нужному нам региону продвижения:
Это также позволит проанализировать среднюю позицию именно в нужной нам стране, а не среднюю по всему миру.
Если интересует срез по устройствам, т.е. как продвигается сайт в мобильном и десктопном поиске, какие там CTR и средняя позиция.
Аналогично настройке, указываем только “Устройство”:
После обновления и получения данных по такой выборке делаем выгрузку:
Можно сделать выборку определенных страниц и посмотреть, как продвигается ПК и мобильные версии.
- Какие позиции? Если позиция сильно отличается – возможно есть проблемы юзабилити этой версии?
- Какой CTR? Если к примеру, на мобилке кликабельность отсутствует, а на ПК с CTR всё порядке – проверьте отображение сниппета в мобильной выдаче (нужно улучшение микроразметки, внедрение AMP-страницы).
Если у вас жесткое сегментирование трафика в рекламе по регионам и устройствам, то можно также выгрузить запросы по страницам учитывая сразу эти 2 пункта:
Использовать данные выгрузки запросов можно для:
- Проработки семантики;
- Доработки контента;
- Контекстной рекламы;
- И т.п.
White Label
Еще интересная функция, доступная на версии PRO, подойдет для:
- Вебстудий – можно брендировать отчеты, включая их в свои бизнес процессы;
- Инхаус-специалистов – можно инициировать отчёты с определённым отделом или ответственным;
- Фрилансеров – персонализация отчетов и повышение со стороны клиента.
Для включения персонализированных отчетов необходимо использовать следующие настройки:
</ul></ul></ul></ul>
- Включить white label;
- Загрузить логотип в форматах png, jpg, svg;
- Указываем “Имя”;
- Заполняем “Email”;
- Телефон в произвольном формате;
- Название вашей компании;
- URL сайта.
Аудит качества оптимизации
Получить отчет с основными ошибками и рекомендациями можно через меню “Экспорт”:
- По кнопке “Аудит качества оптимизации (PDF)” – получаем основной отчет.
- По кнопке “Все доступные отчёты (основные + XL)” – также среди отчетов будет указанный выше.
Пример отчета в формате PDF: Аудит сайта soltyk.ru
Заключение
Краулер Netpeak Spider – очень многофункциональный инструмент в руках SEO-специалиста.
Есть много интересных фишек, которые можно проанализировать комбинируя Netpeak Spider с другими SEO-сервисами.
Обновлено: 22.02.20213969
</ol></ol> Рейтинг: /5 – голосов
В данной статье мы разберем, как парсить сайты с помощью «Netpeak Spider» (десктопной программы для парсинга) на примере интернет-магазина. Он позволяет собрать практически любые данные в автоматизированном режиме.
Довольно часто «Netpeak Spider» используют для сбора информации о товарах с интернет-магазинов с возможностью выгрузки в Excel таблицу. Это необходимо для того, чтобы в дальнейшем импортировать эти данные на свой сайт.
Парсинг товаров с сайта интернет магазина в таблицу
Если Вы обладатель сайта агрегирующего/продающего товары по тематике, к примеру, «Оборудование для общепита», и в Вашем интернет-магазине представлена эта категория, то парсер товаров с сайта поставщика в таблицу Вам может определенно пригодиться.
Связано это с тем, что далеко не все поставщики могут дать Вам выгрузку товаров в формате excel. Либо она обладает излишними данными, которые предполагают большой объем работы: картинки, вставленные непосредственно в таблицу, много ненужной информации, макросы и т.д. Проще взять нужную Вам информацию с исходного сайта, выбрав в автоматизированном режиме именно те данные, которые нужны Вам. Потом можно выгрузить их в эксель или csv таблицу, чтобы в дальнейшемимпортировать с помощью «WP All Import» на WordPress сайт или какой-то другой. К слову, не обязательно работать с интернет-магазинами, поскольку «Netpeak Spider» позволяет добывать любую информацию с любых сайтов.
Популярный сервис
SEO аудит сайта
Netpeak Spider(Нетпик спайдер)
Вы с таким же успехом можете парсить текстовую информацию, к примеру: новости, аналитику, картинки, агрегировать статистику и эту информацию импортировать в WordPress с помощью «WP AllImport». Либо можно применять дополнительные фильтры и продолжать работать с полученной информацией в табличном виде.
Так же можно пускать ее в дальнейшее производство. Например, спарсить e-mail по списку сайтов и в дальнейшем пустить их в систему е-mail рассылок. Либо на основе этих e-mail создать аудиторию для ретаргетинга в рекламной компании (Вконтакте или через Яндекс аудитории).
Если Вам интересно узнать более подробно о том, как импортировать товары или данные из уже полученной таблицы, то Вы можете посмотреть вот это видео. Там я подробно рассказываю, как это сделать на примере сайта на WordPress и плагина «WP All Import».
Настройки парсинга данных «Netpeak Spider»
Если мы хотим собрать информацию по всем товарам, которые есть в каталоге интернет-магазина, то нам необходимо заполнить следующие поля:
- Название товара;
- Цена;
- Описание;
- Картинка.
Для этого нам необходимо проделать следующие действия:
- Открываем «Netpeak Spider»;
- Заходим в «Настройки» — «Настройки парсинга»;
- Ставим отметку «Использовать парсинг HTML данных;
- Извлекать необходимые данные можно несколькими путями — XPath, CSS-селектор и регулярные выражения;
- Можно просто находить какую-то необходимую информацию и считать, сколько раз она встречается без сохранения в таблицу;
Более подробно почитать про каждый из вариантов извлечения данных Вы можете ниже
Всего в программе 4 вида поиска:
- Содержит → считает количество вхождений искомой фразы на странице. Работает в формате «только поиск», то есть не извлекает никаких данных. Самый простой вид поиска: представьте, что Вы, просматривая исходный код страницы, просто нажимаете Ctrl+F и вводите необходимую фразу – программа делает это автоматически на всех страницах и показывает, сколько значений она нашла.
- RegExp → извлекает все значения, соответствующие заданному регулярному выражению. Работает в формате «поиск и извлечение». Следующий по сложности вид поиска: позволяет больше кастомизировать процесс, значительно расширяя возможности поиска, однако требует базовых знаний регулярных выражений. Читайте подробнее о регулярных выражениях.
- CSS-селектор → извлекает все значения необходимых HTML-элементов на основе их CSS-селекторов. Работает также в формате «поиск и извлечение». Достаточно простой и, в то же время, мощный способ извлечения данных: например, необходимо указать всего лишь одну букву «a», чтобы вытянуть все ссылки со страницы. Читайте подробнее о CSS-селекторах (на английском языке).
- XPath → извлекает все значения необходимых HTML-элементов на основе их XPath. Работает также в формате «поиск и извлечение». Самый мощный способ выборки данных, однако, требует определённых знаний и опыта. Читайте подробнее об XPath.
Копирование необходимых элементов через xPath
Для того чтобы скопировать необходимые элементы через xPath, открываем наш сайт и карточку товара, где содержится информация. Чтобы проще идентифицировать элементы, нам понадобится консоль вебмастера:
- В Chrome она вызывается клавишей F12.
- После этого нажимаем на иконку выделения со стрелкой.
- Выделяем необходимые элементы — название товара в данном случае.
- Консоль подсвечивается, и мы нажимаем правой кнопкой мыши для выбора опцию «копировать в xPath».
После того данные в xParth скопированы, можно переходить в настройки парсинга. В том поле, мы будем парсить название, необходимо выдрать опцию xPath. Туда же ставим скопированный xPath из консоли вебмастера.
После этого можно проделать те же самые шаги для «Описания». Если Вы хотите скопировать не весь текст, то можно выделить только определенную его часть. Но так как в данном примере нас интересует полностью описание, то я выбираю тег, который содержит «Описание» и «Особенности».
Особенности парсинга картинок с помощью CSS-селектора
Спарсить картинку xPath нам не поможет. Связано это с тем, что если мы выделим ее таким же образом и попробуем скопировать xPath, то он будет уникальный для конкретного товара. То есть он будет содержать id конкретной картинки, и когда парсер «Netpeak Spider» будет переходить по карточкам других товаров, то там этот id будет меняться, и мы никакую информацию не скопируем.
Поэтому в данном случае, чтобы скопировать url картинки, мы воспользуемся таким методом извлечение данных, как CSS-селектор. Чтобы Вам проще было работать с CSS-селекторами, я рекомендую установить расширение для Chrome оно называется «ChroPath». После установки он будет находиться в правом верхнем углу экрана.
Нас интересует значение src для тега image, так как в нем содержится url нашей картинки. Так как у этого тега img нет какого-то определенного класса, то мы можем посмотреть, что является его родителем.
Мы видим, что этот тег img находится внутри div с id «ShowCardImage». Соответственно, в настройках CSS-селектора мы можем указать, чтобы он нашел на странице элемент с id «ShowCardImage», а потом нашел внутри него img и скопировал значение атрибута src.
С помощью расширения ChroPath открываем вкладку в консоли вебмастера. Здесь можно выбрать, какой тип селектора мы хотим использовать.
Я указываю в ChroPath: id «#ShowCardImage», и потом говорю, какой элемент меня интересует, т.е. img.
После этого я нажимаю «Enter» и он мне выдает информацию согласно CSS-селектору: подсвечивает картинку, которую нашел, а так же фрагмент кода, который соответствует данному CSS-селектору.
Я сразу могу протестировать, правильно ли работает мой CSS-селектор. Здесь, в настройках программы «Netpeak Spider», мне нужно указать, что меня интересует значение атрибута src. Переходим в настройки, в поле «Картинка» и выбираем опцию извлечения данных «CSS-селектор». Далее нужно поставить правило, чтобы найти элемент с id «ShowCardImage» и внутри него найти картинку (тег img), а потом из него извлечь значение атрибута src.
Ограничение области парсинга
Далее, чтобы не парсить лишних данных и не собирать ненужную информацию необходимо ограничить область поиска парсера. Нас не будут интересовать страницы «О компании», «Статьи», «Контакты», «Блог», «Акции» и те разделы сайта, где не содержится информация о товарах. Мы хотим спарсить только каталог, взять информацию о товарах, а все остальные страницы просто игнорировать.
Для этого в «Netpeak Spider» можно задать правила:
- Заходим в «Настройки» — «Правила», нажимаем «Добавить правила»;
- Ставим «Включить» в таблицу только те url, которые содержат папку /goods/.
- Если мы перейдем на какие-то другие страницы сайта, то увидим, что они сгруппированы по категориям.
- Если мы посмотрим по всем страницам каталога товаров, то увидим, что они все идут через категорию /goods/. То есть в адресе сайта у нас содержится папка /goods/, и все товары содержатся в ней.
Создание групп правил в «Netpeak Spider»
При необходимости мы можем создавать группы правил и выстраивать логику работы между ними.
- Логическое условие «или». Например, если я хочу парсить информацию только из разделов каталога или статей, то я могу добавить второе правило включать в исходный отчет только раздел /goods/ и /articles/ и поставить между ними логическое условие «или». То есть если страница содержит, либо другое, то нужно добавлять ее в отчет.
- Логическое условие «и». Правило «и» применяется, когда url должен удовлетворять всем правилам, и таким образом фильтровать и экономить ресурсы парсера.
После того как мы задали условия парсинга и правила обхода сайта – сохраняем настройки и нажимаем «ОК»
Экспорт результатов парсинга
В параметрах мы выбираем тот вид работы, который должен производиться программой. То есть я выбираю здесь исключительно парсинг. Меня не интересует, чтобы «Netpeak Spider» собирал информацию по индексации, битым ссылками и другим параметрам SEO, которые предназначены для анализа внутренней оптимизации сайта. Это необходимо для ускорения работы, а так же для экономии ресурсов и времени.
После того, как выбрана опцию «Парсинг», можно проставить изначальную ссылку на каталог. После этого «Netpeak Spider» перейдет в указанный раздел и начнет переходить по всем ссылкам, собирая информацию, согласно правилам и настройкам, которые мы указали ранее. Для этого:
- Я ставлю ссылку на каталог, как начальный url.
- После этого нажимаю «Запуск».
- Мы видим на вкладке «Парсер», как происходит сбор данных. Если данные собраны, то нам будет показано, что они есть. Для тех полей, где их нет, мы сможем видеть, что они не собраны.
Когда парсер соберет всю информацию и обойдет весь сайт, можно перейти на отдельную вкладку и сразу все результаты посмотреть:
- Ссылка на страницу товара;
- Название товара;
- Описание (где есть описание – оно подсвечивается, где нет – будет пустым);
- Цена;
- Картинка.
Мы видим, что все исходные данные собраны. После этого мы нажимаем «Экспорт» и сохраняем в нужном нам формате. Далее мы можем пустить эти данные в дальнейшую работу. Либо работать с ними в таблице и запускать дальнейший импорт на основе этих данных на наш сайт.
Заключение
Если у Вас возникли вопросы по работе «Netpeak Spider», то Вы можете задать свой вопрос в комментариях. Я постараюсь максимально подробно на него ответить. Если Вы не хотите разбираться с какими-то техническими моментами, и Вам просто нужен результат, то Вы можете и оставить заявку на обратную связь. Мы обсудим, как я смогу Вам помочь: как организовать парсинг, и как спарсить и импортировать данные на Ваш сайт.
Вы можете скачать Netpeak Spider и бесплатно пользоваться полноценной версией программы течении 7 дней здесь, если вы решите и дальше(после завершения 7 дней пробного периода) пользоваться Netpeak Spider то можете сэкономить 10% воспользовавшись промокодом 14ca4308.
Многие SEO-специалисты практически ежедневно проводят технические аудиты сайтов используя тот или иной софт для краулинга. В 90% случаев это всем известные Screaming Frog SEO Spider либо Netpeak Spider. Обе программы платные, а их стоимость начинается от £149 и $182 в год соответственно (500 бесплатных страниц, доступных в Screaming Frog в учет не берем, так как это не серьезно для более-менее крупных проектов). Согласитесь – не каждый фрилансер-сеошник может позволить себе потратить более 10 000 рублей на приобретение подобного софта. Без сомнений, обе программы достойные, но хотелось бы дешевле, и намного дешевле. А лучше бесплатно ) Конечно, помимо Screaming Frog и Netpeak Spider существует множество других платных и бесплатных аналогичных программ для краулинга сайтов, однако, большинство из них либо имеет более слабый функционал, либо их поддержка и развитие прекращены по неизвестным нам причинам. И если среди платных краулеров особых вопросов «что использовать» особо не возникает (лягушка, нетпик, ну или вебсайтаудитор на крайний случай), то бесплатные аналоги известны далеко не всем. В данной статье мы постараемся осветить данный вопрос. Примеры альтернативных бесплатных SEO-краулеров:Xenu’s Link Sleuth – прародитель веб-краулеров, не обновлялся с 2010 года. Было бы странно, если бы им сейчас еще кто-то пользовался.WildShark – очень простой и бесплатный парсер сайтов от одноименного рекламного агентства. Хотя WildShark SEO Spider имеет больше функций, чем Xenu’s Link Sleuth, однако он все же функционально бедноват. Настройки практически отсутствуют. Подойдет для быстрой оценки технического состояния сайта, но для серьезных аудитов не подходит.Beam Us Up – бесплатный сканер сайтов для ПК, который поддерживает платформы Windows, Linux и MacOS, имеет достаточно информативные отчеты и возможность выгрузки в Excel битых ссылок, редиректов и т.п. ошибок на сайте. Из минусов: парсит только HTML, проект более не поддерживается и не развивается.Webbee – это бесплатный сканер сайтов или списка URL. Программа имеет широкий набор анализируемых параметров, отображает полученную статистику в графическом виде, есть интеграция с Google Analytics. Минусы: визуализация данных на графиках выглядит жутковато, анализируемых параметров могло бы быть и больше, нет возможности фильтрации данных по произвольным полям. Последний релиз был выпущен в 2015 году.LinkChecker – программа предназначена для проверки битых ссылок в HTML-коде и файлах CSS, отсюда ее ограниченность в применении. Работает медленно, давно не обновлялась. Не стоит тратить на нее время.IIS SEO Toolkit – бесплатный SEO-краулер самой Microsoft! Обладает достаточным набором функций для программ подобного рода, скорость сканирования сайтов также на уровне. Однако работает только на Windows 7-8. 10-ка не поддерживается. По всей видимости дальнейшая поддержка программы прекращена.SiteAnalyzer – по набору функций практически не уступает платным аналогам, то есть на 80% программа повторяет основной функционал Screaming Frog и Netpeak Spider. При этом некоторых функций, таких, как «Визуализация ссылочных связей» на графе, нет даже у большинства платных аналогов. Молодой, но уже достойный внимания продукт. Как можно понять из выше озвученного списка, бесплатных альтернатив у платных краулеров предостаточно, однако большинство из них обладают посредственным функционалом, поэтому более подробно я бы хотел остановиться лишь на одной программе из предложенных вариантов – SiteAnalyzer. Программа визуально довольно близка со Screaming Frog SEO Spider, при этом на 80% SiteAnalyzer повторяет основной функционал «лягушки» и имеет русскоязычный интерфейс, поэтому разобраться с ее работой опытному либо начинающему сеошнику не составит большого труда.
Быстрый доступ к проектам
Основным отличием SiteAnalyzer от Screaming Frog является возможность хранения всех сайтов в единой базе в виде списка проектов. Таким образом, не нужно тратить время на сохранение проекта на диск и последующую загрузку данных с диска – просто выбираем нужный проект из списка и через несколько секунд получаем все его страницы с подробной информацией по каждой из них.
Визуализация данных
Визуализация ссылочных связей на графе предназначена для визуального отображения внутренней перелинковки сайта, что дает дополнительное представление о структуре сайта и помогает определить хабовые страницы и разделы. Не лишним будет упомянуть, что веб-краулеров с возможностью визуализации ссылок на графе во всем мире наберется не больше, чем пальцев на одной руке, поэтому наличие данной функции в бесплатной программе особенно ценно.
Расчет PageRank
Вкладка PageRank предназначена для расчета и отображения численного значения внутреннего ПейджРанк для каждой страницы сайта (рассчитывается исходя из внутренней перелинковки всех страниц сайта). Таким образом, SEO-специалист сможет проанализировать, какие страницы получают больше всего внутренних ссылок и при необходимости скорректировать перелинковку сайта для перенаправления ссылочного веса на более важные страницы.
Проверка индексации страниц
В программе существует возможность проверки индексации страниц в поисковой системе Яндекс через Яндекс XML. Таким образом, после сканирования сайта вы сможете проанализировать, какой процент страниц вашего сайта находится в индексе Яндекса без использования сторонних сервисов.
Дашборд
Вкладка Дашборд позволяет отобразить подробный отчет о текущей оптимизации сайта на одной странице путем отображения всех найденных ошибок и указанием степени их критичности. Помимо этих данных в отчете присутствует указание общего показателя качества оптимизации сайта, рассчитываемого по 100-бальной шкале относительно текущей степени его оптимизации. Дополнительно имеется возможность экспорта данных вкладки «Дашборд» в отчет в формате PDF.
Заключение
Сегодня мы рассмотрели бесплатные варианты программ для технического аудита и выяснили, что при желании можно найти вполне достойные замены платным инструментам и прилично сэкономить бюджет, практически ничего не потеряв в качестве проведения аудита сайтов.Используемые источники:
- https://soltyk.ru/instrumentyi/netpeak-spider
- http://www.azoogle.ru/netpeak-spider/
- https://habr.com/ru/post/498394/