Содержание
Подбирать каждый ключевик для контекстной рекламы вручную – это довольно щепетильно и трудозатратно. Да и не обязательно усложнять себе жизнь, так как есть специализированные инструменты, которые помогают частично автоматизировать этот процесс.Почему частично? Потому что без вмешательства специалиста всё равно не обойтись. Однако благодаря этим инструментам сбор семантики уже не занимает так много времени.В этой статье мы познакомим вас с самыми популярными сервисами для сбора семантики для Яндекс.Директа и Google Ads и кратко пройдемся по их функционалу. Начнем с бесплатных программ.
Расширения для браузера Яндекс Wordstat
Использовать Яндекс Wordstat по старинке, то есть копипастить подходящие запросы – вчерашний день. Использование бесплатных расширений для браузера дает гораздо больше возможностей.Рассмотрим основные из них на примере плагина Wordstat Assistant. После установки его панель управления находится в левой области страницы Яндекс Wordstat. Итак, плагины Вордстата позволяют:1) Формировать собственный список ключей, отбирая из выдачи Вордстата нужные в пару кликов.Знаком «+» около каждого результата вы добавляете фразу в свой список. Кликом по кнопке «Добавить все» – все фразы со страницы выдачи, на которой сейчас вы находитесь:
Итак, плагины Вордстата позволяют:1) Формировать собственный список ключей, отбирая из выдачи Вордстата нужные в пару кликов.Знаком «+» около каждого результата вы добавляете фразу в свой список. Кликом по кнопке «Добавить все» – все фразы со страницы выдачи, на которой сейчас вы находитесь: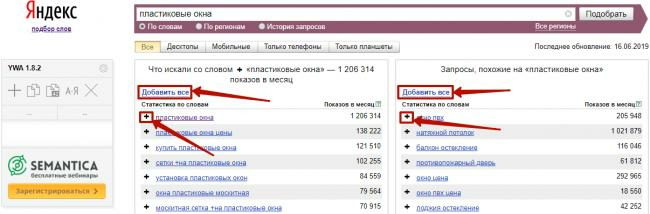 Удалить фразы можно из результатов поиска Яндекс Wordstat (1) или прямо из панели управления (2). Либо крестиком вверху панели управления (3), если нужно очистить весь список:2) Видеть автоматически рассчитанное количество фраз и частотность по списку благодаря встроенным счетчикам;3) Добавлять собственные ключи:Правда, частотность для них не подтягивается из данных Вордстата, а обозначается знаком вопроса.4) Сортировать список ключей по частотности, алфавиту и порядку добавления.5) Сохранять список в аккаунте Яндекса и редактировать при повторном открытии.Более сложный плагин – WordStater. Он поддерживает все базовые функции, плюс свои уникальные вещи.WordStater включает три вкладки:1) Общий список из результатов Wordstat;2) Список минус-слов;3) Без минусов и дублей – список фраз, отфильтрованный от минус-слов.В верхней строке плагина вы видите общее количество собранных фраз (1) и можете найти конкретную фразу в списке (2):Теперь – об уникальных возможностях WordStater, связанных со сбором семантики.1) Полуавтоматический сбор – с помощью специальных горячих клавиш:
Удалить фразы можно из результатов поиска Яндекс Wordstat (1) или прямо из панели управления (2). Либо крестиком вверху панели управления (3), если нужно очистить весь список:2) Видеть автоматически рассчитанное количество фраз и частотность по списку благодаря встроенным счетчикам;3) Добавлять собственные ключи:Правда, частотность для них не подтягивается из данных Вордстата, а обозначается знаком вопроса.4) Сортировать список ключей по частотности, алфавиту и порядку добавления.5) Сохранять список в аккаунте Яндекса и редактировать при повторном открытии.Более сложный плагин – WordStater. Он поддерживает все базовые функции, плюс свои уникальные вещи.WordStater включает три вкладки:1) Общий список из результатов Wordstat;2) Список минус-слов;3) Без минусов и дублей – список фраз, отфильтрованный от минус-слов.В верхней строке плагина вы видите общее количество собранных фраз (1) и можете найти конкретную фразу в списке (2):Теперь – об уникальных возможностях WordStater, связанных со сбором семантики.1) Полуавтоматический сбор – с помощью специальных горячих клавиш:
- Ctrl+Shift+A – для добавления ключей с текущей страницы;
- Ctrl+Shift+(стрелка вправо) – со следующей, и т.д.
Так вы быстрее соберете много фраз, однако есть риск «схватить» за это капчу.2) Исключение из выдачи Вордстата ранее минус-слов, заданных вручную или собранных из выдачи.Активируйте минусацию, откройте вкладку «Сбор минус-слов»:Или исключите слова прямо в выдаче Вордстата:3) Генерация ключевых фраз в «Комбинаторе слов»:Работает она по принципу перемножения:Подробнее об этих и других возможностях расширений Яндекс Вордстат смотрите здесь.
Планировщик ключевых слов Google
Этот инструмент доступен во всех регионах, где работает Google Реклама. Перейти в него можно напрямую по ссылке или в «Инструментах и настройках» аккаунта Google Ads.Подбор новых слов – одна из базовых функций. Остановимся именно на ней.Алгоритм Google может выполнять поиск по названиям товаров или услуг (максимум 10 исходных вариантов) и / или контенту целевой страницы:Вот пример поиска по продукту и адресу страницы:В результате Google выдает свои варианты ключевых слов по исходным, которые задали вы. Сразу со статистикой (либо прочерком, если данных недостаточно), чтобы вам было проще принимать решение о добавлении вариантов в кампанию:Полное руководство по Планировщику ключевых слов Google читайте здесь.
Key Collector и СловоЕБ
Это комплексная десктопная программа, в которой есть буквально всё для работы с контекстной рекламой, в том числе сбор семантического ядра.Чтобы сделать парсинг в Key Collector, добавляем фразы:Запускаем парсинг. Рекомендация: выбирайте глубину 2. Так вы сразу получаете не только результаты парсинга, но и дополнительную выдачу по каждому из них.Подробнее настройки описаны здесь.Также Key Collector позволяет очистить семантическое ядро от «мусора», а именно:
- Ключевиков, которые содержат ненужные слова;
- Повторов слов;
- Стоп-слов (информационные запросы, города, в которых не действует предложение, «бесплатно», «дешево», субъективные определения и т.д.);
- Запросов с нулевой частотностью.
Есть бесплатный аналог Key Collector – СловоЕБ. Основное его ограничение – в источниках. Он работает только с левой и правой колонкой в Wordstat, Rambler.Adstat и поисковыми подсказками Яндекс и Google.Для сравнения: Key Collector поддерживает всё вышеперечисленное, плюс Google Ads, подсказки Mail, Wordstat полностью и системы аналитики, установленные на сайте (Google Analytics, Яндекс.Метрика, LiveInternet).Другие ограничения программы СловоЕБ:
- Проверяет частоту запросов только по Wordstat, а КК также по Yandex.Direct, Google.Ads, LiveInternet, Rambler.Adstat, APIShop.com;
- Оценивает конкурентность запросов для Яндекс и Google, в то время как в КК 4 формулы оценки KEI, которые можно менять вручную.
Однако этого функционала будет вполне достаточно, если у вас небольшой проект.
Rush Analytics
Это платный сервис, включающий бесплатный триал на 14 дней, который автоматизирует задачи при парсинге семантического ядра, а именно:
- Проверяет позиции в Яндекс и Google;
- Выполняет кластеризацию запросов;
- Собирает ключевые слова на основе поисковых подсказок;
- Собирает данные из Яндекс.Wordstat в облаке;
- Проверяет индексацию URL;
- Анализирует текст и другие зоны страниц.
С помощью Rush Analytics можно удобно и быстро собрать ключевые слова из Яндекс Wordstat (левой и правой колонок) и Google Рекламы, а также поисковые подсказки.Всё просто: вы задаете свой запрос, по которому хотите найти похожие, и получаете результаты, вместе с данными по частотности. Без риска «схватить» капчу.Всё начинаете с создания задачи.Далее по порядку задаете регион и настройки сбора семантики.Вы можете собирать ключи из левой и правой колонок или с данными по частотности. Укажите, сколько страниц выдачи Вордстата использовать для сбора запросов. Естественно, чем больше страниц – тем больше результатов.Если вы выбираете вариант «Сбор частотности», вы можете указать, какой тип частотности вам нужен.Далее загрузите запросы списком или в виде файла в xls / xlsx.Также в Rush Analytics есть возможность почистить семантику от стоп-слов – для этого сервис предлагает готовые списки стоп-слов по тематикам.Когда всё готово, отслеживайте процесс сбора на странице задач.
Keyword Tool
Это условно бесплатный инструмент, с помощью которого можно также собрать подсказки автозаполнения с Google, YouTube, Bing, Amazon, eBay и App Store.Чтобы им воспользоваться бесплатно, регистрация не нужна. Просто заходите сюда, вводите запросы и получаете результаты.Слева можно использовать фильтр для результатов и задать минус-слова.Правда, чтобы перейти на русскоязычную версию сайта, нужно переключить язык внизу страницы.Результаты со статистикой доступны только в платной версии.
 Как получить Key Collector бесплатно и как забыть про заморочки с Семантическим Ядром
Как получить Key Collector бесплатно и как забыть про заморочки с Семантическим ЯдромБукварикс
Букварикс помогает подбирать ключевые слова по запросу / запросам или по домену / доменам сайтов.Причем при подборе по списку запросов можно задавать минус-слова, чтобы сразу исключать из результатов нецелевые фразы.Дополнительно есть опция «Анализ доменов», благодаря которой вы можете:
- Выяснить, какие слова подойдут для заданного вами сайта;
- Подсмотреть, какие ключи используют ваши конкуренты, но не используете вы.
Еще одна фишка сервиса – бесплатная база 40+ миллионов уникальных рекламных объявлений Яндекс.Директ по России, Украине, Беларуси, Казахстану, которые можно использовать для вдохновения.На выбор есть бесплатный онлайн-инструмент, бесплатная десктоп-версия и платный бизнес-аккаунт за 995 рублей.
SemRush
Этот инструмент в бесплатной версии позволяет сформировать под один запрос по 10 фраз в широком и фразовом соответствии под заданный вами регион. По каждой вы видите частотность.Чтобы начать поиск, нужна регистрация.Регион вы задаете в начале:В процессе вы можете посмотреть фразы по этому же ключу, но по другим регионам и почерпнуть оттуда идеи.К сожалению, в SemRush не предусмотрена возможность подбирать семантику по списку ключевиков.
Serpstat
Serpstat – платная многофункциональная программа с бесплатным пробным периодом.Она позволяет скачать не только поисковые запросы, по которым рекламируются ваши конкуренты, но и их тексты объявлений и посадочные страницы. А также оценить уровень конкуренции (частотность и цену за клик) по заданному вами ключу.Примерно так выглядит отчет Serpstat:
SpyWords
С помощью онлайн-сервиса SpyWords вы можете найти ключевые фразы, которые используют конкуренты в Яндекс или Google, и добавить их в свои рекламные кампании.Плюсом к этому можно посмотреть тексты их объявлений, позиции в выдаче, дневной бюджет.Если внимательнее разбирать отчеты SpyWords, можно найти ключи и нишу, где большой спрос, но мало конкурентов или дешевые клики. Сервис доступен только платно – от 3 300 рублей в месяц без учета скидок.
Почему не стоит целиком полагаться на автоматизацию
Есть, как минимум, два случая, когда без ручного труда не обойтись.Во-первых, не всегда семантическое соответствие гарантирует смысловое соответствие. Машинный интеллект не сможет выявить все синонимы и переформулировки, или может отнести какие-то варианты к синонимам по ошибке.Особенно если вы имеете дело со сложными продуктами. Например, подготовка сжатого воздуха, или осушка воздуха. Больше расширений можно насобирать по слову «осушка».Но среди результатов в Wordstat мы можем увидеть и «осушка газа», и «адсорбционная осушка», и «осушка компрессора». Это разные продукты, а значит, разный спрос. Выявить это можно только вручную.Во-вторых, очистка семантического ядра от «мусора». Этот процесс почти невозможно автоматизировать полностью. Готовых минус-списков и данных об отказах из систем аналитики недостаточно для 100% точности.P.S. При выборе инструмента для сбора семантического ядра ориентируйтесь на то, из каких источников он ищет поисковые запросы, смотрит ли поисковые подсказки и учитывает ли минус-слова по вашей тематике.И обязательно проверяйте результаты автоматического парсинга!Статья в тему:Семантическое ядро для контекстной рекламы: алгоритмы для разных типов кампаний
Всем привет, меня зовут Ожгибесов Александр, на форумах я известен как PermProd или AOzhgibesov. Я зарабатываю тем, что занимаюсь продвижением сайтов в заветный ТОП 10, а также делаю хорошую семантику для ваших проектов. Сегодня я расскажу вам об инструментах и способах, которые позволяют собирать мне семантику, и как их использовать. О том, что такое семантическое ядро и как его правильно составить, вам расскажут другие ребята, я же поведаю о том, как максимально быстро обработать собранные ключи для продвижения вашего сайта, и какими инструментами при этом можно пользоваться. А начнем мы с самых азов.
wordstat.yandex.ru
Этот сервис позволяет за одну минуту оценить правильность выбранной ниши для вашего информационного или коммерческого проекта. Возьмем, к примеру, запрос «простуда» – вбиваем запрос в вордстате и получаем значение в 378 400 показов в месяц, что, на первый взгляд, кажется очень неплохим результатом. Если мы будем делать информационник по этой теме, у нас точно не будет проблем с получением трафика, а вот с доходом могут возникнуть некоторые проблемы. И здесь нам на помощь приходит замечательная «история запросов». Мы видим явный спад с летом и примерно стабильную картину с осени по зиму. Поэтому если вы только выбираете нишу, в которой вам работать, старайтесь обращать внимание не только на частотность, но и на сезонность ключей. Если вы будете работать по теме простуды и ваш примерный заработок с сентября по март будет 30 тысяч рублей, то будьте готовы к тому, что летом он будет 10 тысяч рублей. На самом деле я не случайно решил вспомнить о таком инструменте, как вордстат. В своей работе я постоянно использую его, как для формирования входным групп, так и для первичной оценки ключей, не будешь же каждый раз лезть в Key Collector, чтобы проверить точную частотность ключа.
Словоёб – бесплатный аналог Key Collector.
Итак, мы выбрали тематику, оценили сезонность ключей и пришло время собрать семантику для нашего проекта. Именно с этой программы я и начал работу с семантикой, она прекрасно справляется с задачей, которая стоит перед новичком. Спарсить данные вордстата, получить данные поисковой выдачи, и на этом всё. Выглядит эта программа так же, как и её старший брат, она позволяет также выбирать регион парсинга, решает простейшие задачи по работе с группами, в общем, всё то, что необходимо новичку. Чуть ниже я расскажу вам о всех прелестях Key Collector, но это будет позже, а пока подробно рассмотрим его бесплатный аналог.Группы. Начнем с того, что Словоёб обладает весьма скромными возможностями для работы с группами, но куда же без них. Например, при парсинге вы можете указать, в какую группу вам собирать те или иные ключи и это круто при работе с большими проектами (о которых я чуть подробнее расскажу в разделе KC). Как ни странно, Cловоёб умеет даже автоматически добавлять группы для парсинга, для этого делаем следующее. В окне парсинга с Wordstat забиваем входные запросы и нажимаем вот на эту кнопочку. Результатом станет следующее Представьте, как это удобно, когда вам необходимо спарсить данные для 1500 ключей, а вы не хотите собирать их в одну группу, чтобы затем группировать это всё вручную. Очень круто, советую пользоваться этой функцией. Фильтрация запросов. Словоёб не умеет создавать шаблоны фильтров, он вообще мало что умеет, но отфильтровать запросы от большего к меньшему он может, уже хорошо. Стоп-слова. Куда же без стоп-слов. Например, мы можем задать список фраз, которые не желаем видеть в нашем ядре, и программа автоматически найдет запросы, в которых есть полное или частичное вхождение. Сбор подсказок. Поисковые подсказки – это очень крутая вещь, которая позволяет существенно расширить пул запросов для работы. Собирать их Словоёб тоже умеет.Сбор KEI. Словоёб также сможет получить кол-во главных страниц и других заголовков, которые входят в выдачу Яндекс и Google по определенному ключу. На этом возможности этого продукта кончаются. Самая большое неудобство – это невозможность переносить запросы между группами, что подразумевает отсутствие возможности кластеризации. Ну а что делать, хочешь крутой продукт – плати деньги.
Key Collector – друг, брат и лучший в мире инструмент.
KC – это старший и более опытный брат Словоёба. Я остановлюсь лишь на тех инструментах, которые включены в данную программу и которые существенно экономят мне время при работе с ядром. Группы. Чуть выше я рассказал о скромных возможностях Словоёба при работе с группами, а теперь пора продемонстрировать возможности, которые предоставляет в этом вопросе KC. Представьте, что у вас есть крупный интернет-магазин по продаже постельного белья, и вам необходимо собрать семантику под весь ассортимент. Вы знаете, что есть постельное белье из разных материалов, размеров и разных производителей, скажем есть 300 различных модификаций и под каждую вам необходимо собрать семантику. Несложными арифметическими действиями мы понимаем, что спарсить нужно от 300 до 1000 различных запросов. Одной группой пользоваться неудобно, поэтому можно создать определенное кол-во входных групп, как это автоматизировать я указал выше. Да ладно, хватит теории, покажу, как это выглядит на примере. Почему круто пользоваться группами? Да потому что у вас получается ни одно огромное СЯ, которое вам нужно рассортировать, удалить мусор и т.д., а 300-500 мини-ядер, с которыми работать куда удобнее. Фильтрация запросов Это был пример из уже созданного мной ядра, теперь покажу некоторые фишки, которые помогают мне в моей работе. Для этого я займусь парсингом подсказок и данных wordstat по запросу «простуда», а на основе этих данных продемонстрирую то, что ежедневно использую в работе. У нас получилось 850 запросов, среди которых «простуда на губе», «лечение простуды», «водка с перцем от простуды» и куча других. Соберем точную частотность, чтобы получить данные по подсказкам. Если вы собираете точную частотность через Директ, то дополнительно парсятся его данные, бюджеты контекста: стоимость клика, эти данные нам не нужны, удалить их очень просто. Заходим в вкладку данные, очистка данных и выбираем «Очистить статистику Yandex.Direct». Я понимаю, что можно правой кнопкой пройтись по колонкам и нажать стереть данные, но представьте, что ядро состоит не из одной группы, а из 1000, этот инструмент очень упростит вашу жизнь. В Key Collector у каждой колонки есть замечательная кнопочка, которая называется «Редактировать условия фильтрации». С помощью неё мы и будем производить начальную фильтрацию наших запросов. Изначально удалим все то, что имеет точную частотность меньше 20. В итоге из 850 у нас осталось всего 302 запроса, с которыми мы и будем работать. Что касается фильтрации. Авторы программы позаботились и сделали уже готовые фильтры для некоторых колонок, например, колонки Фраз. Вы можете увидеть запросы, которые состоят из n количества слов, или выделить те, которые содержат в себе различные символы. Анализ неявных дублей. Это ещё один инструмент в Key Collector. Он позволяет удалить вам часть дублей, которые появились в процессе парсинга. Найти его легко: он находится во вкладке данные. После запуска он самостоятельно найдет дубли, выглядит это так. Анализ групп. Следующий инструмент, который многие используют при работе с ядром, находится все в той же вкладке. Он позволяет сгруппировать наши запросы по составу фраз (можно выбрать силу по составу), по отдельным словам, по поисковой выдаче. Данные KEI я парсить не стал, поэтому покажу только по отдельным словам и составу фраз.По отдельным словам. Запросы формируются по наличию какого-либо слова, предлога и т.д. Это очень удобно и позволяет найти группы данных, например, в этой группе содержаться запросы, которые связаны с простудой на губах. По составу фраз. Здесь группировка идёт более интеллектуально, однако, придется просмотреть все группы, чтобы удалить весь мусор из ядра. Лично я использую в работе все варианты и каждый раз перепроверяю ядро. Чтобы сильно не увеличивать статью, я дам вам ссылку на пост, в котором Михаил Шакин рассказывает о данных инструментах и показывает практические наработки. А ещё он снял 9 минутное видео, в котором наглядно рассмотрел все инструменты. Для многих эта информация окажется очень полезной.
Прокси и аккаунты.
Если ваше ядро состоит из 100-200 запросов, вам, естественно, даже задумываться не нужно о таких словах, как прокси или аккаунты Яндекса с подтвержденным телефоном. Но если вы работаете с 10000 ключей и больше, то задуматься явно стоит. Мало того, что такое количество ключей обработать быстро с одного ip нереально, так вам светит бан на 2 недели от wordstat. Для своих нужд прокси я покупаю исключительно у Vladimir-AWM. С Владимиром я работаю на протяжении нескольких месяцев, до него я перепробовал с десяток различных поставщиков, в которых успешно разочаровался. У него же я покупаю недорогие, но очень качественные индивидуальные приватные прокси, его тема также присутствует на форуме webmasters.
Расширение ядра за счет сторонних сервисов и программ.
Далеко не всегда парсинг ключей даёт весь пул запросов, которые нам необходимы. Я расскажу вам о паре сервисов, которые использую лично я. Прямой эфир Яндекса. Суть данной программы проста. Вводим туда запроc, по которому мы хотим получить ключи, он нам их достает из прямого эфира. После этого мы можем сохранить эти данные в обычный TXT, а затем загрузить в Key Collector и обработать. Эти запросы программа собрала за пару минут работы, а вы представьте, что ей под силу, если оставить её на сутки или неделю. На данном форуме есть тема, где автор рассказывает, как можно использовать его программу. Ссылка на скачивание. PRODVIGATOR.Ru Данный сервис позволяет выгрузить список запросов, по которым продвигается тот или иной сайт в поисковых системах. На выходе вы получите Excel файл со списком запросов, которые также можете забить в Key Collector и проанализировать. Плюс никогда не помешает знать, по каким запросам вас обходит ваш конкурент. К этому же списку можно отнести сервисы SpyWords и advODKA.Сторонние сервисы. К ним можно отнести русскоязычную базу Пастухова, базы метрики и ещё с десяток различных сервисов и сборок. Рассказывать я о них не стану, при желании вы самостоятельно сможете изучить информацию по данным вопросам, а мы пойдем дальше.
Сервис Rush Analytics – автоматизированный сервис для подбора семантического ядра
Вы далеко не новичок в сфере SEO, знаете, что такое Key Collector, как парсить, кластеризовать запросы, но у вас нет доступа к компьютеру, а клиент срочно просит ядро (да, я знаю, из меня никудышный маркетолог) – именно тут вам на помощь придет Rush Analytics. Не так давно в интернете начали появляться сервисы для кластеризации запросов и парсинга. Далеко не для всех ядро – это таблица из 15-20 данных, для многих достаточно данных вордстата и кластеризации запросов. Итак, что же умеет этот сервис? Спарсим данные Вордстата по запросу «простуда». Задаем название проекта и регион для парсинга, выбираем, что необходимо парсить, задаем список запросов и стоп-слов, ждемс ) Кстати, за весь этот процесс сервис попросил у меня всего 3 рубля, это дешевле, чем купить KC, то же самое предоставляет сервис в вопросе парсинга подсказок поисковых систем Яндекс и Google. Полученный файл имеет следующий вид. В нем мы видим запросы, частотность, по листам раскиданы данные, которые мы вводили при запуске проекта. Кластеризация запросов идет на основе поисковой выдачи, что на данный момент является одним из лучших вариантов, однако, никто не отменял руки и голову, поэтому любой такой файл необходимо проверять ручками. Если говорить в целом, то кластеризация вполне годная, хотя я бы не стал расширять настолько сильно пул запросов для одной статьи. Скачать файл вы можете отсюда.
Что ещё почитать?
Совсем недавно модератор TbIKBA сделал обзор сервиса для кластеризации запросов Just magic. Я не буду переписывать его обзор, а просто поставлю на него ссылку – при желании прочитаете. Кроме того, Сергей Кокшаров, известный также как Devaka, выложил краткий обзор 50 инструментов для работы с семантическим ядром. Также подобную статью написал и Александр Алаев. С небольшими перерывами на канале Игоря Бакалова также появляются обзоры, которые помогут новичкам разобраться в работе с ядром.
Выводы.
На сегодняшний день семантика является неотъемлемой частью любого сайта, что подтверждается таким обилием сервисов. Я сделал небольшой дайджест тех инструментов, которые ежедневно использую в своей работе, надеюсь, что данная информация будет полезна вам в ваших начинаниях. И, конечно же, спасибо вам за внимание, если вы дочитали моё творение до конца.
Используемые источники:
- https://yagla.ru/blog/kontekstnaya-reklama/sbor-semantiki-dlya-kontekstnoy-reklamy/
- http://webmasters.ru/forum/f160/sostavlenie-semanticheskogo-yadra-instrumenty-kotorye-uskoryayut-i-povyshayut-effektivnost`-dannoi-zadachi-69373/